
AI nei sistemi GxP
AI nei sistemi GxP:
un nuovo paradigma per CSV, qualità e data integrity

Questa variazione di natura richiede un ampliamento dell’approccio tradizionale alla validazione. Le linee guida pubblicate negli ultimi anni, es. GAMP 5 2nd ed. e GAMP AI Guide del 2025, chiariscono che la valutazione di un sistema basato su AI deve includere anche il modello, i dati di training, le tecniche di addestramento, gli iperparametri e il modo in cui viene monitorata la stabilità del modello nel tempo. Non si tratta quindi di aggiungere un nuovo documento alla validazione, ma di allargare il perimetro e includere elementi che finora erano considerati estranei al concetto di "software".
Le normative di riferimento rimangono valide. Il 21 CFR Part 11 e l’Annex 11 continuano a richiedere audit trail completi, controlli degli accessi, sicurezza dei dati e salvaguardia dell’integrità dei record. Tuttavia, l’AI introduce rischi aggiuntivi, come la presenza di “bias” nei dataset, la possibile degradazione delle performance durante l’uso reale o l’eccessiva dipendenza da condizioni operative specifiche. Tutti aspetti che richiedono nuovi controlli.
Per comprendere meglio questa trasformazione è utile un esempio concreto.
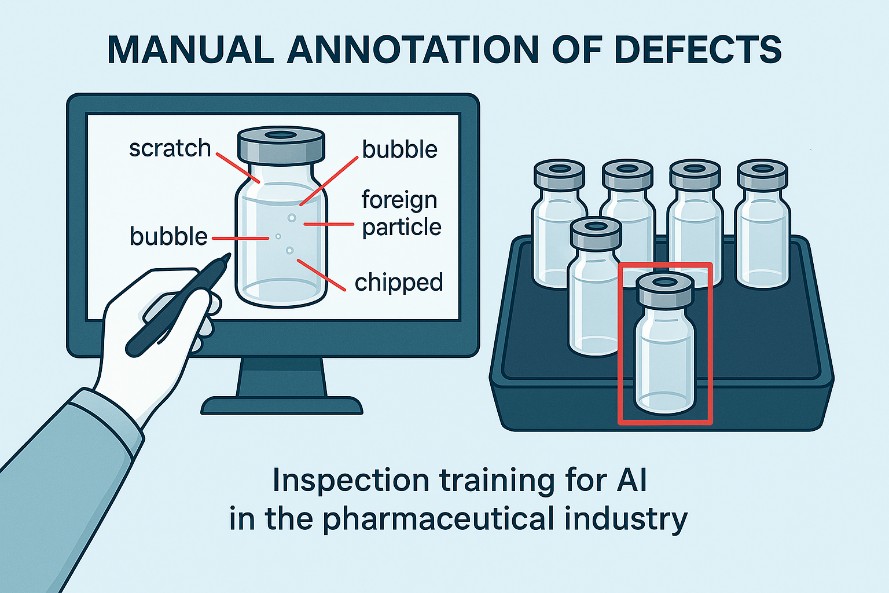
Si consideri un sistema di ispezione visiva per fiale o flaconi. Prima che l’AI possa essere utilizzata in produzione, deve essere addestrata su un grande numero di immagini.

Queste immagini vengono raccolte da un lotto rappresentativo e analizzate una per una da un team di operatori esperti. Ogni immagine deve essere etichettata manualmente, identificando difetti come graffi, scheggiature, bolle, particelle, microfratture, anomalie del tappo o livello di riempimento non corretto. È un’attività lenta e meticolosa, ma è la fase più importante dell’intero processo, perché questo set di etichette rappresenta la verità su cui il modello imparerà a distinguere i prodotti conformi da quelli non conformi.
Durante l’addestramento, la rete neurale rielabora più volte l’intero dataset. Confronta ciò che prevede con ciò che è stato etichettato dagli operatori e modifica progressivamente i propri pesi interni. Iterazione dopo iterazione, riduce l’errore e migliora la sua capacità di riconoscere i difetti. Il training si conclude solo quando le performance si stabilizzano. A quel punto il modello viene congelato e può essere distribuito in produzione. Tuttavia, anche questo non è sufficiente.
A livello europeo, l’AI Act del 2024 aggiunge un ulteriore livello di responsabilità. Il regolamento introduce una classificazione basata sul rischio e richiede che i sistemi ad alto rischio, categoria in cui ricadono molte applicazioni GxP, rispettino regole più severe in materia di governance dei dati, robustezza, documentazione e supervisione umana. È un approccio che si integra perfettamente con la logica della convalida e spinge le aziende a strutturare processi più maturi.
Per chi lavora nella CSV non si tratta di reinventare tutto, ma di spostare il focus. Le attività note rimangono, ma devono essere applicate a un oggetto diverso: non più solo software deterministici, bensì modelli che cambiano nel tempo, dipendono dai dati e richiedono un monitoraggio continuo. Di conseguenza, sarà necessario valutare la rappresentatività dei dataset, controllare le trasformazioni dei dati, definire criteri oggettivi di accettazione dei modelli, gestire i cambiamenti nel comportamento del sistema e attuare un monitoraggio continuo delle prestazioni. Anche il Data Integrity si estende infatti, oltre ai principi classici, diventano importanti la tracciabilità del dataset di training, la capacità di spiegare come il modello prende determinate decisioni e la verifica che i dati utilizzati siano adeguati allo scopo. Sono aspetti che richiedono un’organizzazione con ruoli e responsabilità ben definiti e una cultura del “dato” ad una versione 2.0.
Articolo a cura di Andrea Bussi - CSV Business Unit Manager, S.T.B. Valitech S.r.l.
- GAMP 5 - A Risk-Based Approach to Compliant GxP Computerized Systems (Second Edition). 2022.
- ISPE GAMP Guide: Artificial Intelligence. 2025.
- Sarkar C. et al. Artificial Intelligence and Machine Learning Technology Driven Modern Drug Discovery and Development. International Journal of Molecular Sciences, 2023, 24(3), 2026. [https://www.mdpi.com/1422-0067/24/3/2026] Licenza: CC BY 4.0.
- European Medicines Agency (EMA). Guiding Principles of Good AI Practice in Drug Development. [https://www.ema.europa.eu/en/documents/other/guiding-principles-good-ai-practice-drug-development_en.pdf]
- European Commission. EudraLex Volume 4 - Annex 22: Artificial Intelligence (draft). [https://health.ec.europa.eu/document/download/5f38a92d-bb8e-4264-8898-ea076e926db6_en?filename=mp_vol4_chap4_annex22_consultation_guideline_en.pdf]
- S. Food and Drug Administration. 21 CFR Part 11 - Electronic Records; Electronic Signatures. [https://www.ecfr.gov/current/title-21/chapter-I/subchapter-A/part-11]
- Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) Action Plan. 2021. [https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-software-medical-device]
- European Medicines Agency (EMA). Reflection Paper on the Use of Artificial Intelligence in the Medicinal Product Lifecycle. 2021 [https://www.ema.europa.eu/en/documents/scientific-guideline/reflection-paper-use-artificial-intelligence-medicinal-product-lifecycle_en.pdf]
- European Union. Artificial Intelligence Act [https://artificialintelligenceact.eu]
- Gazzetta Ufficiale UE [https://eur-lex.europa.eu]
- Nagy, Zsolt. Artificial Intelligence and Machine Learning Fundamentals. Packt Publishing, 2018.
- Musiol, Martin. Generative AI: Navigating the Course to the Artificial General Intelligence Future. John Wiley & Sons, 2024.
- European Commission - EU Annex 11 (GMP Guidelines) [https://health.ec.europa.eu/system/files/2016-11/annex11_01-2011_en_0.pdf]
- European Commission - EudraLex Volume 4 (GMP) [https://health.ec.europa.eu/latest-updates/eudralex-volume-4_en]
Ultime
Novità


